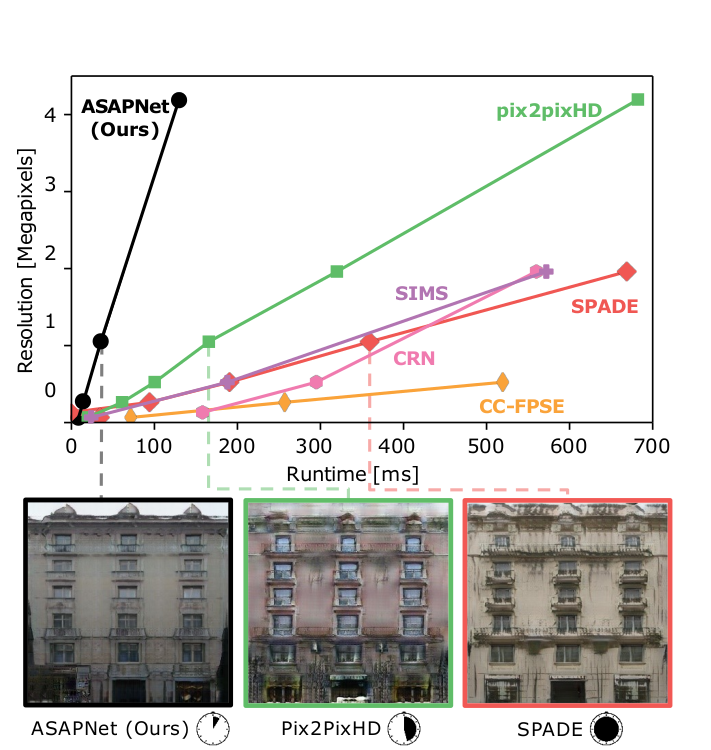
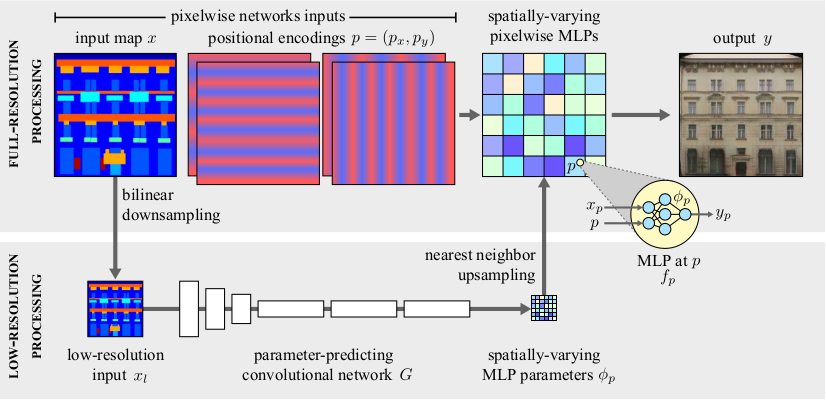
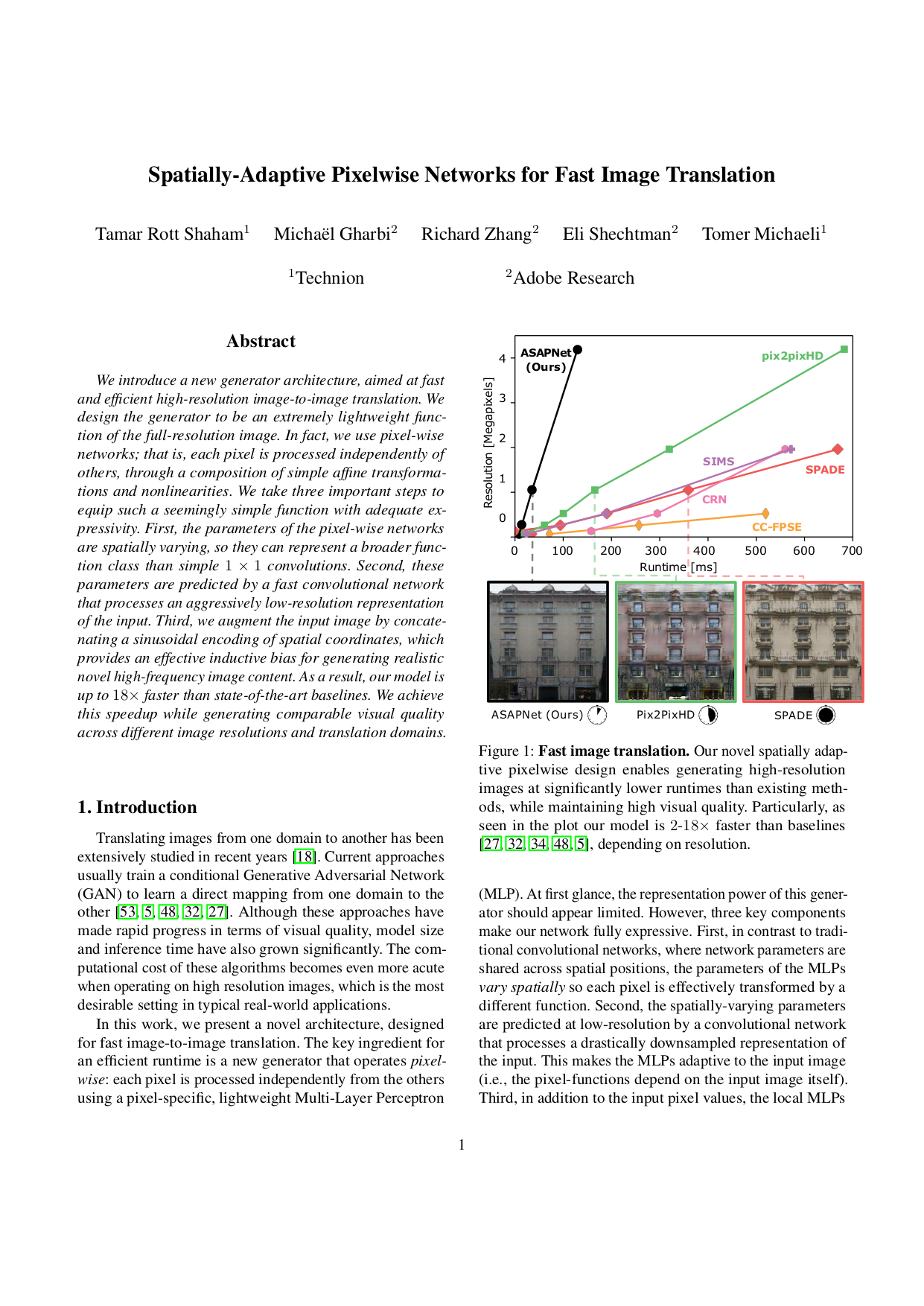
Xihui Liu, Guojun Yin, Jing Shao, Xiaogang Wang and Hongsheng Li,
Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis,
NeurIPS 2019
Taesung Park, Ming-Yu Liu, Ting-Chun Wang and Jun-Yan Zhu,
Semantic Image Synthesis with Spatially-Adaptive Normalization,
CVPR 2019
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, Bryan Catanzaro,
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs,
CVPR 2018
Xiaojuan Qi, Qifeng Chen, Jiaya Jia, and Vladlen Koltun,
Semi-parametric Image Synthesis,
CVPR 2018
Qifeng Chen and Vladlen Koltun,
Photographic Image Synthesis with Cascaded Refinement Networks,
ICCV 2017
|